Day29: multi step workflow
Intro
-
- 首先是我們今天架設的 workflow 的正確題數:
print(f"{correct}/{correct + incorrect}")
10/10 # 破台啦!
-
- 接著是它的實際長相:
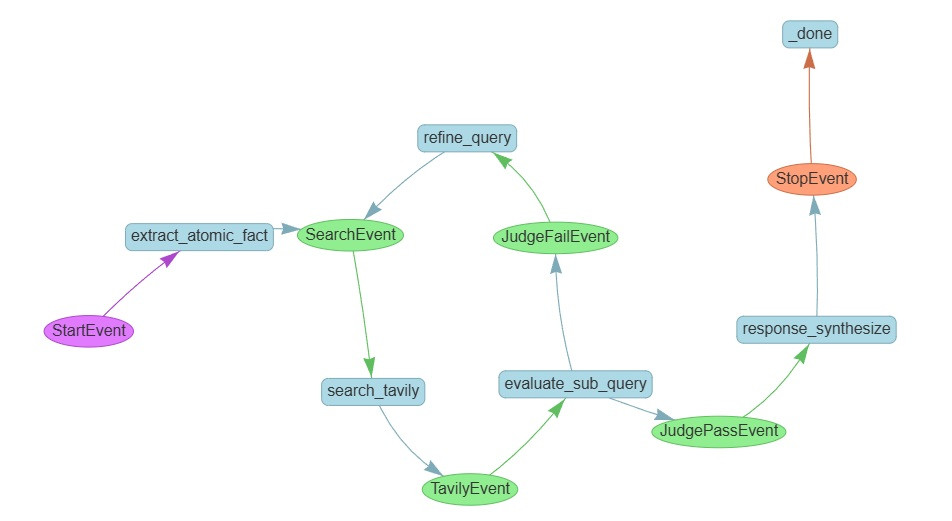
- 藍色長方形,放的是處理邏輯,在 workflow 裡,這叫 step
- 圓形,放的是資料,在 workflow 裡,這叫 event
-
- 以及一筆它的實際回答作為範例展示:
"exam": "題目: 有關腧穴之國際譯名,外丘之編號為何?
選項:\n A: GB33\n B: GB34\n C: GB35\n D: GB36\n",
"feedback": "根據提供的參考資料,外丘穴的國際標準代碼是GB36,因此選項D最符合題意。"
"ans": "D"
"reference_answer": "D"
"context": " - subquery: 外丘穴 國際標準代碼為何\n - subanswer: 外丘穴的國際標準代碼是GB36 [1]。\n - subquery: GB35 的中文穴名是外丘嗎\n - subanswer: 不是。GB35 的中文穴名是「陽交」,而「外丘」是 GB36 [1][2]。\n",
-
- 最後是整個過程所產生的副產物:基於考題所生成的 (question, context, answer) 對

-
由於這是從選擇題考題所產生的資料,因此你可以預期它會比直接從 context 生成的 question, answer 對 "更不像中文閱讀測驗",實際應用也更多
-
到這,也總算完成了我們在開篇預定的主題 1.2: 從問題生成 (question, context, answer) 對
-
今天的完整程式碼包含所產生的資料都可以在: notebooks找到
我們來看一下相比昨天又做了哪些改動吧!
Action:
我們來逐個 step 看一下內容
extract_atomic_fact step / SubQuestionQueryEngine
我們昨天所遇到的本質問題是:
- 系統有找到相關的 context,但是我們的 context 沒辦法支持我們完整回答整題單選題 (找不全)
我們的解法是:
- 在最一開始的時候,就把單選題切成 k 個待驗證的原子問題,回答這幾個問題,就可以回答這題單選題,藉此避免掉了這個找不全的可能
- 範例題目:
{
"query": "題目: 有關手少陰心經的「通里穴」,下列敘述共幾項正確?1手少陰心經的郄穴 2馬丹陽天星十二穴 之一 3距離靈道穴五分 4配內關,治心絞痛\n選項:\n A: 1\n B: 2\n C: 3\n D: 4\n",
"reference_answer": "C",
"atomic_facts": [
"通里穴是否為手少陰心經的郄穴?",
"通里穴是否列入馬丹陽天星十二穴?",
"通里穴與靈道穴距離是否為0.5寸?",
"通里穴配內關是否治心絞痛?"
]
}
search_tavily step
- 每一個 待驗證的 atomic_fact,都會使用 tavily 進行檢索,固定檢索 5 筆資料
- 只要某一個待驗證的 atomic_fact 有對應的檢索資料了,我們就會發送 TavilyEvent
- 透過
ctx.send_event(tavily_event)
for atomic_query, search_query in zip(atomic_querys, search_querys):
search_results = tavily_searcher.search(
search_query, max_results=MAX_RESULTS
)
rv = tavily_parser(search_results, search_query)
tavily_event = TavilyEvent(atomic_query=atomic_query,
search_query=search_query,
tavily_results=rv)
ctx.send_event(tavily_event)
evaluate_sub_query step
- 每有一個子問題檢索完成(tavily_event),evaluate_sub_query step 就會執行一次,並且發出對應的結果
- evaluate_sub_query 的 input 有兩個,
- 一個是原始的 atomic fact
- 以及 tavily 檢索回來的 k 個結果
- evaluate_sub_query 的 output 是一個 dictionary,包含以下兩個 key
- judgment: bool 用來指出這次 tavily 的 5 個檢索是否有足夠的證據支持我們的 atomic_fact
- feedback:
- 如果 judgment 是 true: 則要以 cite 的方式指出是哪個檢索有提到相關的證據
- 如果 judgment 是 false: 要說明這次都檢索到了什麼,建議下次的檢索要用什麼
- 以下是一個範例輸出:
"response": {
"judgment": true,
"feedback": "是,腹哀屬足太陰脾經穴位,並為足太陰與陰維之會 [0][1][2]。"
}
- 這邊的一個重點是我們使用了Day10: CitationQueryEngine 與 Workflow的技巧,用來整理我們雜亂的 context 藉此避免最後合成答案時 context 雜訊太多的問題
- 另一個重點是我們拋棄昨天逐 node 驗證的方法,改為一次看一個 query,不然真的太慢了
- 此外,若是 judgment 是 true,就會發送 JudgePassEvent 給最後的 response_synthesize
- 若是 judgment 是 false,就會發送 JudgeFailEvent 給我們下一個要講的 refine_query step
refine_query step
- 這個步驟相對單純,但卻是我們整個 workflow 的核心,處理的是: 若是一個 atomic fact 找不到支持怎麼辦?
- 他的 input 有兩個:
- 原始要確認的 atomic fact
- judgment 給出的 feedback
- 以下是一個 judgment 為 false 的範例:
# atomic fact: 《刺灸心法要訣》是否禁針俞府?
"response": {
"judgment": false,
"feedback": "提供的來源未提及《刺灸心法要訣》是否禁針俞府:Source [0] 論述雷射針灸;Source [1] 為《素問》相關引文與中膂俞等穴描述;Source [2] 為傷科教材概述;Source [3] 為“中府”詞條;Source [4] 為醫書介紹,均未涉及《刺灸心法要訣》對俞府的禁針記載。建議檢索關鍵詞「刺灸心法要訣 俞府 禁針」。"
}
- 這個 feedback 會連同原始的 atomic fact 一起被放到 prompt 裡,提出下一次檢索的建議
- 而 refine_query step 的輸出格式則被定為和原始的 SearchEvent 一樣,形成閉環
- 額外要說明的一點是: 我們這邊保留了一個參數 max_round ,用來避免無止盡的重複檢索下去
- 若 max_round 發生,現在的處理是會直接捨棄這個 atomic face (但我們沒有發生這件事)
response_synthesize
- 最後就是彙整所有驗證過後的 atomic fact,用來產生最後的回答
- 這邊是一個整理好的
context 的範例
# subquery: 通里穴是手少陰心經郄穴嗎
- subanswer: 不是,手少陰心經的郄穴是陰郄 [4]。
# subquery: 通里穴屬馬丹陽天星十二穴嗎
- subanswer: 是,通里穴屬於馬丹陽天星十二穴 [0][1]。
# subquery: 通里穴與靈道穴相距0.5寸嗎
- subanswer: 是的,通里穴與靈道穴相距0.5寸 [0]。
# subquery: 通里穴配內關能治心絞痛嗎
- subanswer: 可以。冠心病心絞痛的推薦取穴以心俞、厥陰俞為主,配內關、通里等,適用於心絞痛 [2];臨床體針方案亦以內關為主並配通里等,治療心絞痛總有效率約84.62%~89.2% [3]。此外,通里與內關常用於按摩以緩解心悸、胸悶、心絞痛等症狀 [1]。
- 藉由這樣整理好的 QA pair 作為 context,我們基本上可以排除因為 context 太雜亂導致的選錯
- 那剩下的問題就是確保我們每一個的 atomic fact 有照實回答
- 關於這部分,因為已經變成是 (question, reference_context, reference_answer),處理起來也相對不複雜
- 此外這邊還有一個小修正: 我們改了 synthesize 的 prompt
ANSWER_PROMPT = PromptTemplate(
template="""
你是一個中醫考題專家,請根據下面的題目回答單選題。
請遵守以下規則:
1. 使用所提供的參考資料作答。
2. 輸出 JSON 格式。
3. JSON 需包含兩個 key:
- "feedback" :根據所提供的 context 分析各選項
- "ans" : 選擇最貼近題意的答案 (A/B/C/D)
4. 不要加入題目之外的說明或其他文字。
# {query}
參考資料 (context):
# {context}
請直接輸出 JSON:
"""
)
- 藉由顯示的要求要在 feedback 基於 atomic fact 排除選項,再做出選擇(本來是給答案再解釋),我們消除了最後的一個錯誤,而得到全對的結果
- 你可以在 prompts.py 找到我們這篇用到的所有 prompts
That's it!
Summary:
最後的一個系列裡,我們完整經歷了一個 dataset 的通關過程,
-
day25 我們以直接 prompt 回答當作 baseline,加入 wiki-search有了一點進步
-
day26 我們把 evaluator 加入到我們的 pipeline 裡,若 evaluator 說不好,我們就用 tavily 再查一次
- 我們發現有些錯誤其實檢索就已經有找到答案了,但是最後選擇題還可以填錯,轉而懷疑是 context 太亂
-
day27 我們介紹 label-studio 這個工具,用來客製化 UI 格式來協助我們查看每步的資料,並且獲得少量的人工標註結果
- 再次驗證我們的想法,現在問題出現在 synthesize
-
day28 我們 prompt llm 來把檢索回來的資料擷取成關鍵片段,並且把整個 pipeline 做成 workflow 的形式
- 本來以為到這邊就結束了,但沒想到又發現了新問題: 我們雖然有檢索到相關的結果,但並不支持我們完整回答整個問題
- 這邊核心的問題在於我們整個流程固定只會檢索 2 次,一次 wiki 一次 tavily,導致我們有所謂 "找不全" 的問題
- 最後就是今天,我們引入了前面研究過的 subquestion 技巧,以及 citation 技巧,來把當前的 benchmark 刷到滿分
- 重點是這個 workflow 嗎? 當然不是,讓這個 workflow 多做幾題,就會發現其他的錯誤了
- 但現在的我們,也已經掌握了夠多的工具以及技巧,能夠面對問題、接受問題、處理問題、放下問題
Day30: 總結
- 我本來想說大家都是寫程式的,應該很懂什麼叫做從 0 開始,所以第一篇就打著 day 0,結果誰知道放眼望去只有我每天 day 的數字比別人少 1
- 這邊就趁這最後一點時間,來把我的 day30 也補上
- 參賽跟完賽的心得我就不多說了,我的沒什麼特別,跟大多數的人一樣,覺得這個真的不是人幹的,但還是要好好感謝老婆小孩支持,讓我在這 30 天能夠有時間把每天的文章寫出來
- 下面主要想要完善的是: 要來把 day0 所構建的 index 拿回來重製,讓這系列的文章可以跳著讀
關於我們在 day0 大放厥詞說要做的 5 個 topic
主線任務
- 獲取 (context, question, answer) 對
-
1.1 從 context 出發: 完成從 Youtube 獲取 context -> prompt llm 產生 QA
-
1.2 從 question 出發: 從考題(pdf)出發 -> 由 llm 產生 (question, context, answer)
-
1.3 從答案出發
- 篇幅關係刪除,這邊主要的想法是:
- 1.1 從 context 出發的問題,很容易變成其實是閱讀測驗
- 1.2 從 question 出發的問題,需要先有"考題" 這個強假設
- 1.3 其實就是直接來生成考題,解決要先有考題的強假設
- 具體來說類似於生成單選題裡的干擾選項,用來產生"非閱讀測驗"的問題
- 搭建 Label Studio,獲得 ground truth
- RAG baseline 的搭建
- 驗證框架的探索
- 提升方法的探索
支線任務
關於 結構化的 output
關於 觀測與log
關於用 workflow 土炮一個 ...
最後是一些本來想寫但是最後沒寫到的
好啦! 30天結束了,謝謝每個有花時間看文章的各位,我們有緣再見!


 iThome鐵人賽
iThome鐵人賽